


مقدمة: حول الحاجة للمترجمات
عند النظر إلى أي نص برمجيّ من إحدى لغات البرمجة الشهيرة، سنلاحظ أنه مكتوبٌ باستخدام كلمات ورموز غريبة إلا أنها مألوفة بالنسبة لنا، فهي على الأقل بالحروف الإنجليزية وتتضمن بعض التعابير والمصطلحات المتداولة بحياتنا اليومية. مع الأسف فإن عرض نفس البرنامج على المعالج لن يؤدي لأي نتيجةٍ مشابهة: الحروف والرموز والتعابير المكتوبة باللغة الإنجليزية هي أمور مستحيلة الفهم بالنسبة للمعالج بشكلٍ مباشر، فهو يفهم لغة وحيدة: اللغة الثنائية المؤلفة من سلاسل الأصفار والواحدات.
بهذه الصورة وكي تكون البرامج التي نقوم بكتابتها مفهومةً بالنسبة للمعالج، فإننا سنحتاج لمن يفسرها له ويشرح ما الذي نريده منه بالضبط، فالبرنامج بالنتيجة ليس سوى مجموعة من التعليمات التي نريد المعالج أن يقوم بتنفيذها. بعالم لغات البرمجة يبرز مصطلح “المترجم Compiler” للإشارة إلى البرنامج الوسيط الذي يأخذ على عاتقه مهمة جعل النصوص البرمجية المكتوبة بإحدى لغات البرمجة عالية المستوى مفهومةً بالنسبة للمعالج.
يهدف هذا المقال لشرح المترجم ودوره ضمن نظام معالجة النصوص البرمجية بشكلٍ عام وبسيط.
- اقرأوا أيضًا: مقدمة إلى لغات البرمجة
- اقرأوا أيضًا: ما هي البرمجة الإجرائية Procedural Programming
- اقرأوا أيضًا: ما هي البرمجة كائنية التوجه Object-Oriented Programming
ما هو المترجم Compiler؟
المترجم عبارة عن برنامج يقوم بتحويل الشيفرة المصدرية المكتوبة بإحدى لغات البرمجة عالية المستوى إلى تمثيلٍ منخفض المستوى مع المحافظة على معنى وهدف الشيفرة المصدرية. يتم استخدام مصطلح “الشيفرة المصدرية Source Code” للإشارة إلى النص البرمجيّ المكتوب بإحدى اللغات عالية المستوى، بينما يتم استخدام مصطلح “الشيفرة الهدف Target Code” للإشارة للشيفرة الناتجة عن عمل المترجم، والتي تكون عادةً بإحدى اللغات منخفضة المُستوى. بالإضافة إلى ذلك، يقوم المترجم بإجراء عمليات تحسين على الشيفرة المصدرية لجعلها أكثر كفاءة من ناحية سرعة التنفيذ وحجم الذاكرة التي سيشغلها البرنامج. يمكن تمثيل المترجم بشكلٍ بسيط باستخدام المخطط التالي:
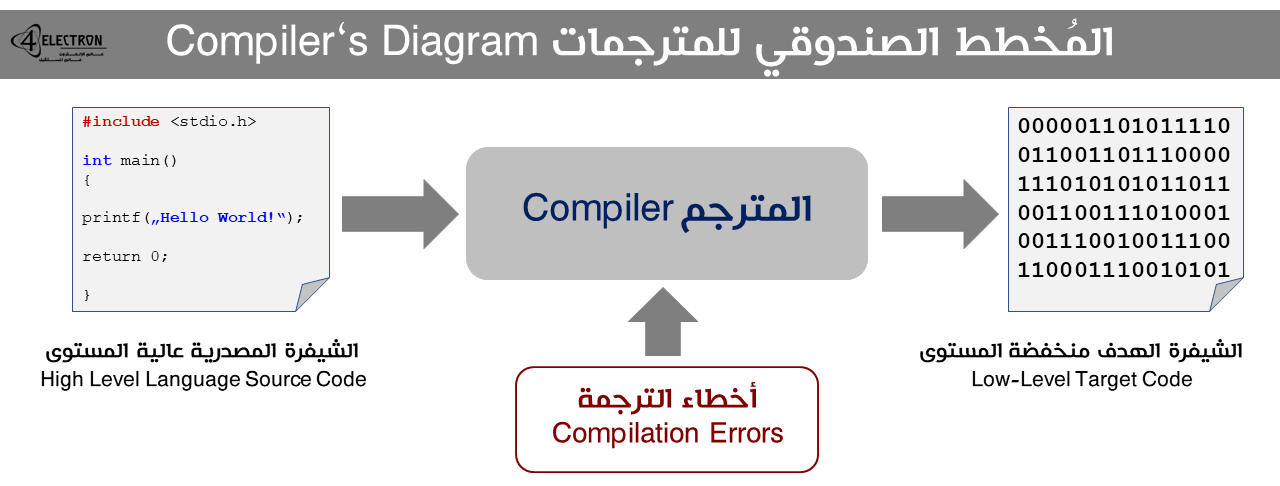
أنواع المترجمات
يمكن تقسيم المترجمات لثلاث أنواع من ناحية كيفية أدائها لمهمتها وتوليدها للشيفرة الهدف:
المترجمات أحادية المسار Single-Pass Compiler: بهذا النمط من المترجمات يتم ترجمة الشيفرة المصدرية عالية المستوى بشكلٍ مباشر للشيفرة منخفضة المستوى بدون أي مراحل وسيطة.
المترجمات ثنائية المسار Two-Pass Compiler: بهذا النمط من المترجمات يتم توليد شيفرة مصدرية وسيطة Intermediate Code وبحيث يُفهم عمل المترجم ككل على أنه قسمين: القسم القريب Front-End والقسم البعيد Back-End. وظيفة القسم القريب هي تحويل الشيفرة المصدرية للتمثيل الوسيط وإجراء عمليات تحليل النص والمفردات بالإضافة لعمليات التحسين، ومن ثم يقوم القسم البعيد Back-End بتحويل الشيفرة المصدرية الوسيطة إلى الشيفرة الهدف مُنخفضة المستوى.
المُترجمات متعددة المسار Mutlipass Compiler: بدلًا من تجزئة عملية الترجمة لقسمين فقط، يوجد مترجمات تقوم بتقسيم عملية الترجمة لعدة أجزاء وينتج عن كلٍ منها شيفرة مصدرية وسيطة، وخرج كل مرحلة يمثل دخل المرحلة التالية. النتيجة النهائية هي الشيفرة المصدرية منخفضة المستوى.
نظام معالجة لغات البرمجة Language Processing System
قبل الدخول بتفاصيل عمل المترجم نفسه والعمليات التي يجريها على الشيفرة المصدرية، يجب توضيح أمر هام: المترجم نفسه هو جزء أكبر من نظام متكامل يتم عبره توليد التعليمات المكتوبة بلغة الآلة والتي يستطيع المعالج فهمها. خرج المترجم غير قابل للتنفيذ مباشرةً من قبل المعالج، كما أن المترجم يعتمد على مراحل أخرى قبله كي يكون قادرًا على أداء مهمته بأفضل شكلٍ ممكن.
يتم استخدام مصطلح “نظام معالجة لغات البرمجة Language Processing System” للإشارة إلى المراحل المختلفة التي يتم عبرها تحويل النص البرمجيّ عالي المستوى إلى لغة الآلة، ويتكون هذا النظام من المكونات والمراحل التالية:
الشيفرة المصدرية Source Code: وهي تمثل البرنامج المكتوب بإحدى لغات البرمجة عالية المستوى والمطلوب تنفيذها من قبل المعالج.
مرحلة ما قبل المعالجة Pre-Processing: تعتبر هذه المرحلة جزءًا من عملية الترجمة نفسها، حيث يتم توليد تمثيل جديد للشيفرة المصدرية عالية المستوى يتم استخدامه من قبل المترجم، والهدف الأساسيّ من هذه المرحلة هي تحديد موّجهات ما قبل البرمجة، التعاريف، المكاتب المضمنة.
المُفسر Interpreter: المفسر عبارة عن برنامج مشابه للمترجم من ناحية قيامه بتحويل الشيفرة المصدرية لتمثيلٍ منخفض المستوى، إلا أن الفرق الأساسيّ يكمن بأن المفسر يقوم بقراءة الشيفرة المصدرية وتنفيذها تعليمةً تلو الأخرى، بينما يقوم المترجم بتحليل كامل النص البرمجيّ ومن ثم توليد الشيفرة منخفضة المستوى. تعتمد بعض اللغات على المفسر كوسيلةٍ لتنفيذ البرامج بدلًا من المترجم.
المُجمّع Assembler: يقوم المجمع بأخذ ناتج عمل المترجم وتحويله لتعليماتٍ مكتوبة بلغة الآلة. ناتج عمل المفسر هو ما يطلق عليه اسم “الملف الكائني Object-File” الذي يتضمن التعليمات التنفيذية بالإضافة للمعطيات اللازمة لتخزين هذه التعليمات ضمن الذاكرة. يتم أيضًا تعريف ناتج عمل المجمع على أنه “تعليمات الآلة القابلة للنقل Relocatable Machine Code“، وهذا يعني أن تشغيل البرنامج نفسه (وهنا نعني التعليمات التنفيذية الخاصة به المكتوبة بلغة الآلة) لا يتطلب وضعه ضمن عناوين محددة في ذاكرة الوصول العشوائيّ RAM، والملفات التنفيذية بصيغة exe. من الأمثلة الشهيرة على تعليمات الآلة القابلة للنقل.
الرابط Linker: ضمن هذه المرحلة يتم ربط وجمع الملفات الكائنية المختلفة الناتجة عن عمل المجمع من أجل توليد الملف التنفيذيّ Executable File. يقوم الرابط بالبحث عن وحدات الاستدعاء التي يتضمنها البرنامج وتحديد مواقع الذاكرة التي تتضمن هذه الوحدات.
المُحمّل Loader: يعتبر المحمل أحد أجزاء نظام التشغيل ووظيفته هي تحميل الملف التنفيذيّ الناتج عن عمل الرابط ووضعه ضمن الذاكرة ومن ثم تشغيله.
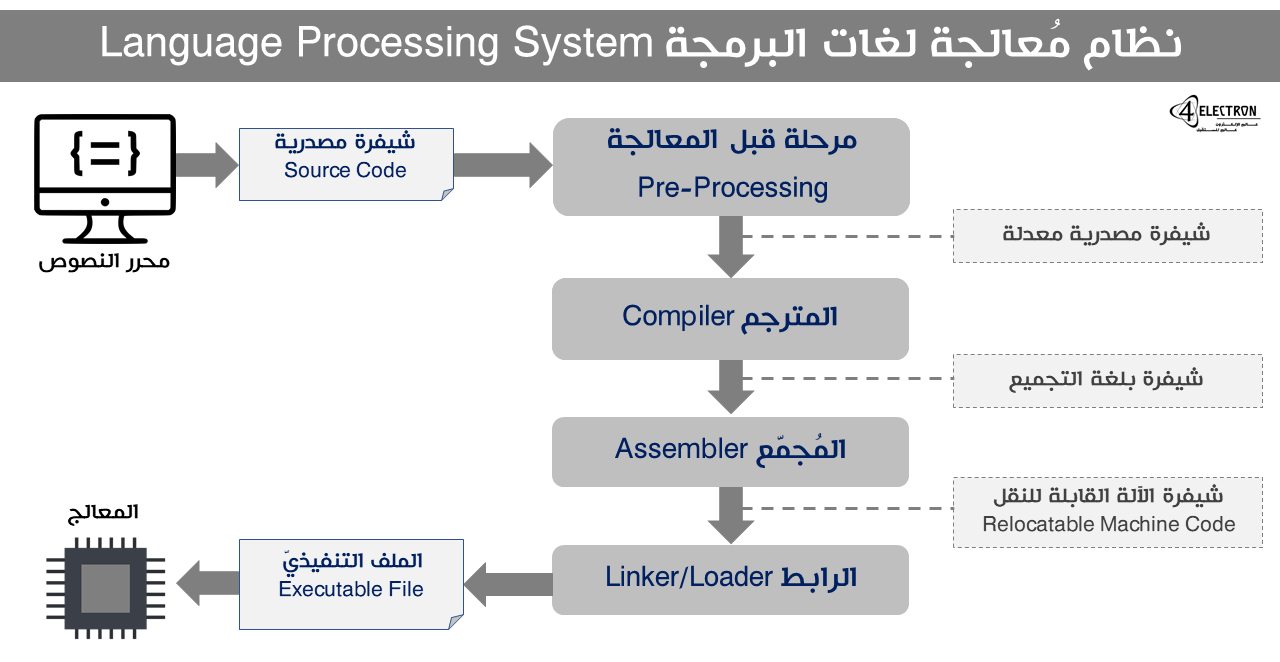
مراحل عمل المترجم Compiler Phases
كما وجدنا، فإن المترجم نفسه يمثل خطوةً ضمن خطوات المعالجة اللازمة لتحويل النص البرمجيّ من شكله عالي المستوي إلى تعليمات لغة الآلة القابلة للتنفيذ من قبل المعالج، ولكن هذا لا يعني أن المترجم نفسه هو مرحلة مستقلة بحد ذاتها، بل يتكون هو أيضًا من مجموعة من الخطوات، وبشكلٍ عام يُمكن تقسيم عمل المترجم إلى قسمين أساسيين:
- مرحلة التحليل – النهاية القريبة Analysis Phase / Front-End
- مرحلة الاصطناع – النهاية البعيدة Synthesis Phase / Back-End
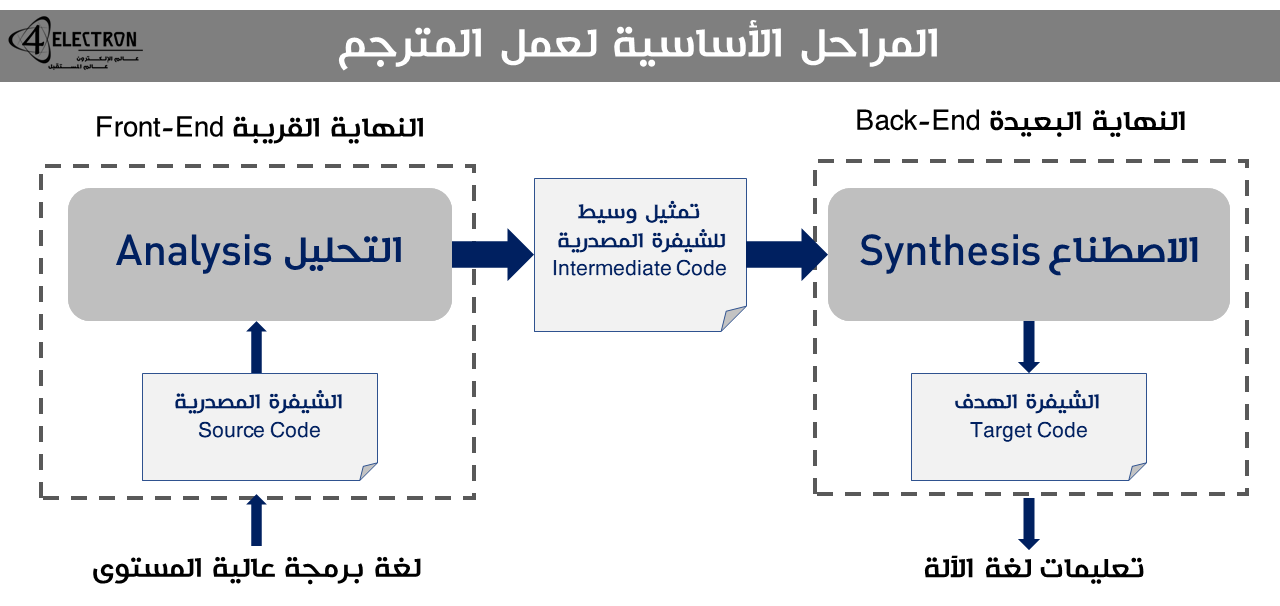
يتم استخدام مصطلحات “النهاية القريبة Front-End” و “النهاية البعيدة Back-End” كوسيلةٍ للإشارة إلى طبيعة الكود الذي يتم التعامل معه، ففي مرحلة التحليل (أي النهاية القريبة) يتعرض النص البرمجيّ من اللغة عالية المستوى لمجموعةٍ من الخطوات التي تعالجه وفقًا لشكله الأصليّ، أي أنه لا يزال “قريبًا” من الشكل الذي يفهمه المبرمج، في حين أن مرحلة الاصطناع (أي النهاية البعيدة) تتعامل مع النص البرمجيّ بعد تحويله لشكلٍ أكثر قربًا من الآلة وأكثر “بعدًا” عن الشكل الذي يفهمه المبرمج.
المترجم : مرحلة التحليل Analysis Phase
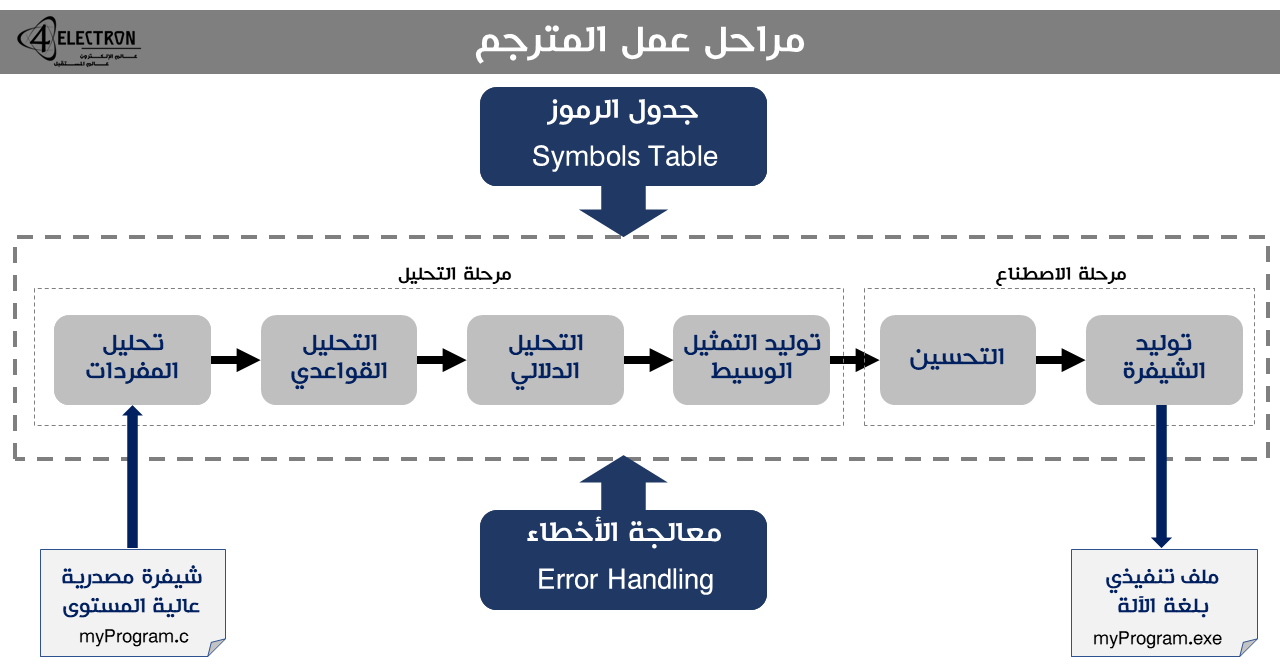
يقوم المترجم ضمن هذه المرحلة بإجراء مسحٍ للشيفرة المصدرية والتحقق من صحته القواعدية والدلالية وذلك بعد تقسيمه لأجزاءٍ مختلفة. في حال نجحت مرحلة التحليل ولم يتم اكتشاف أي خطأ قواعدي ضمن الشيفرة المصدرية سيتم توليد تمثيل وسيط للشيفرة المصدرية Intermediate Code Representation والذي يمثل مرحلةً بين اللغات عالية المستوى ولغة الآلة. بشيءٍ من التفصيل، فإن مرحلة التحليل تتضمن الخطوات التالية:
تحليل المفردات Lexical Analysis: يقوم المترجم ضمن هذه المرحلة بمسح النص البرمجيّ عبر التعرف على الرموز والأحرف التي يتضمنها واحدًا تلو الآخر، مع عدم أخد المسافات الفارغية White-spaces بعين الاعتبار، وكذلك مع عدم أخذ التعليقات بعين الاعتبار. الهدف من مسح النص البرمجيّ هو تحديد العلامات(الرموز) Tokens المتواجدة ضمن النص نفسه، وكمثال، فإن الكلمات المفتاحية المحجوزة Keywords، رموز العمليات، مُحددات المتحولات Identifiers تعتبر جميعها رموز صالحة يتم التعرف عليها ضمن مرحلة تحليل المفردات. لو أردنا أخذ مثال بسيط على كيفية تحليل الرموز وفهمها من قبل المترجم، لنأخذ التصريح البسيط التالي لمتحولٍ اسمه myNumber من نوع Int مع تخزين قيمة 10 ضمنه وذلك بلغة C:
// Declare a variable of type integer and assign 10 as its value
int myNumber = 10; سيقوم المترجم أثناء مرحلة تحليل المفردات بالتعرّف على الرموز التالية:
int <keyword>,
myNumber <identifier>,
= <operator>,
10 <constant>,
; <symbol>في حال اكتشف المترجم أثناء مرحلة تحليل المفردات وجود سلسلة محارف لا تمثل رمزًا صحيحًا Valid Token فإنه سيقوم بتوليد خطأ قواعدي، مثل أن يقوم المبرمج بتحديد نمط المتحول على أنه itn بدلًا من int، فكلا الكلمتين تمثلان سلسلة محارف، والفرق أن الأولى ليست رمزًا صالحًا ضمن قاموس مفردات لغة C، بينما الثانية تمثل رمزًا صالحًا ضمن قاموس مفردات C.
التحليل القواعدي Syntax Analysis: يقوم المترجم بهذه المرحلة بإنشاء شبكةٍ مكونة من الرموز التي تم التعرّف عليها بالمرحلة السابقة تدعى “شجرة التفسير Parsing Tree” أو “الشجرة القواعدية Syntax Tree“، حيث يتم التأكد من صحة توضع الرموز ضمن النص البرمجيّ بشكلٍ صحيحٍ من الناحية القواعدية للغة.
التحليل الدلالي (تحليل المعنى) Semantic Analysis: الخطوة التالية بعملية الترجمة هي إجراء ما يعرف بالتحليل الدلاليّ، وهنا يقوم المترجم بالتأكد من أن شجرة التفسير Parsing Tree التي تم إنشاؤها ضمن مرحلة التحليل القواعدي تمثل نصًا ذو دلالةٍ برمجيةٍ صحيحة. كمثالٍ على ذلك، يتم التأكد بهذه المرحلة من أن المعطيات على طرفيّ عملية الإسناد متوافقة مع بعضها البعض، فلو أن المبرمج قام بإسناد ثابت عددي من نوع الفاصلة العائلة Floating point number إلى متحولٍ من نمط int، فإن هذا الأمر قد يؤدي لتوليد خطأ دلاليّ، على الرّغم من أن الرموز Tokens صحيحة أو أن صحة النص من الناحية القواعدية. ما سيتم تنفيذه بمثل هكذا حالة هو إجراء تقريب Rounding للثابت العددي وإلغاء الأجزاء التي تأتي بعد الفاصلة بحيث يتم تحويله لثابتٍ عددي صحيح من نوع int ومن ثم إسناده للمتحول. كمثال بسيط:
#include <stdio.h>
int main()
{
// Assigning floating number constant to integer variable
int variable = 10.55;
printf("The value saved in the variable is : %d", variable);
return 0;
}بعد إجراء عملية الترجمة للنص البرمجيّ السابق والضغط على أمر التنفيذ، سنحصل على الخرج التالي على الشاشة:
The value saved in the variable is : 10ما حصل بحالة الكود السابق هو التالي: بمرحلة تحليل المفردات عثر المترجم على مجموعةٍ من الرموز الصالحة قواعديًا وقام بتمريرها إلى محلل القواعد Syntax Analyzer، والذي بدوره قام بإنشاء شجرة تفسير تتضمن كل الرموز بهدف تنفيذها، وبما أن توضع الرموز صحيح ولا يوجد أي خطأ تم الانتقال لمرحلة التحليل الدلالي، وبهذه المرحلة عثر المترجم على خطأ وهو إسناد القيمة 10.55 للمتحول int، وهو إسناد خاطئ لأن طرفي الإسناد ليست متوافقة من ناحية النوع، فعلى اليسار هنالك المتحول variable من نوع int الذي يقبل يخزن أعدادًا صحيحة، وعلى اليمين هنالك القيمة الثابتة 10.55 التي تمثل ثابتًا عدديًا من نوع الفاصلة العائمة. ما قام به المحلل الدلالي هو تقريب قيمة الثابت العددي وتحويلها لتصبح 10 ومن ثم تخزينها ضمن المتحول variable والذي سيتم استخدامه لاحقًا من قبل تابع الطباعة printf الذي سيطبع قيمته على الشاشة. ضمن الجملة النصية داخل التابع printf هنالك الرمز %d والذي يشير إلى أننا نريد طباعة قيمة من نوع int، ولو بدلنا هذا الرمز بـ f% فإن ذلك سيؤدي لطباعة 0.00 على الشاشة، ولن يتم توليد أي خطأ قواعدي أو نصي، وذلك لأن النص صحيح من ناحية رموزه وتسلسله القواعديّ، ولكن المعنى المترجم لم يجد قيمةً من نوع الفاصلة العائمة ضمن المتحول variable ليتم طباعتها على الشاشة، ولذلك تم طباعة قيمة 0.00.
توليد التمثيل الوسيط للشيفرة Intermediate Code Generation: بعد انتهاء عملية التحليل الدلاليّ وعدم وجود أي خطأ تستدعي تصحيح النص البرمجيّ، سيتم توليد تمثيل جديد للشيفرة المصدرية يُعرف باسم التمثيل الوسيط، حيث سيتم استخدام هذا التمثيل ليتم لاحقًا توليد الشيفرة المصدرية بلغة الآلة للمعالج الذي سيقوم بتنفيذ البرنامج.
المترجم : مرحلة الاصطناع Synthesis Phase
بعد الانتهاء من مرحلة تحليل النص البرمجيّ والتأكد من سلامته القواعدية والدلالية وتوليد الشيفرة الوسيطة، ينتقل المترجم لمرحلة الاصطناع أي توليد الشيفرة المصدرية الجديدة بلغة الآلة المتوافقة مع المعالج المستخدم، والحديث هنا هو حول لغة التجميع التي تختلف من معالجٍ لآخر بحسب معمارية حزمة التعليمات Instruction Set Architecture الخاصة به، ولذلك فإنه من الضروريّ أن تكون الشيفرة المصدرية متوافقة مع طريقة عمل المعالج.
- اقرأوا أيضًا: ما هي معمارية المعالجات الصغرية Microprocessor Architecture؟
تحسين الشيفرة المصدرية Code Optimization: قبل توليد الشيفرة المصدرية بلغة التجميع، يقوم المترجم بفحصٍ أخير للنص للتأكد من أنه بأفضل شكلٍ ممكن، والمقصود هنا هو إمكانية تنفيذ البرنامج بأعلى سرعة ممكنة وبأقل مساحة تخزين ممكنة على الذاكرة. في حال وجد المترجم سطور برمجية غير ضرورية أو مكررة، فإنه سيقوم بإزالتها للتخفيف من مساحة الذاكرة المحجوزة للبرنامج وكذلك سرعة تنفيذه، إذ أن عددًا أقل من السطور البرمجية يعني عددًا أقل من التعليمات التنفيذية على مستوى المعالج وبالنتيجة سرعةً أكبر بالتنفيذ. كمثالٍ بسيط على عملية التحسين، لنأخذ التصريحات التالية بلغة ++C:
// Variables declaration and assignment
int a;
float b, c, d, e, f;
a = <static_cast>(float) 10.00;
b = c * a;
d = e + b;
f = d; ضمن النص السابق، تم التصريح عن المتحول a من نمط int ومن ثم إسناد قيمة 10.00 له بعد إجراء عملية تغيير للنمط، ومن ثم تم إسناد قيم مختلفة للمتحولات الأخرى. عند تحليل النص السابق، سنجد أنه يمكن اختصاره لعددٍ أقل من الأسطر كما يلي:
float b, c, e, f;
b = c * 10.00;
f = e + b; التعديل البسيط السابق هو أمرٌ يقوم به المترجم نفسه، حيث يلاحظ أنه يمكن استبدال المتحول a بشكلٍ مباشر بثابتٍ عدديّ والتخلص من عملية تغيير النمط، كما أن المتحول d يمكن الاستغناء عنه وإسناد قيمة e + b بشكلٍ مباشر للمتحول f. بهذه الصورة سيتم توليد شيفرة مصدرية ذات سرعة تنفيذ أعلى ومساحة أقل على الذاكرة.
توليد الشيفرة Code Generation: المرحلة الأخيرة من مراحل عمل المترجم هي توليد الشيفرة المصدرية بلغة التجميع والمتوافقة مع المعالج المستخدم لتنفيذ البرنامج. دخل هذه العملية هو الشيفرة المصدرية المُحسنة وخرج هذه العملية هو ما يعرف باسم الشيفرة القابلة لإعادة النقل Relocatable Machine Code بالإضافة لتخصيص قطاعات الذاكرة اللازمة لتنفيذ البرنامج نفسه. ما ينتج عن عملية الترجمة ككل هو ملفٌ (أو ملفات) تعرف باسم الملفات الكائنية Object-Files والتي تتضمن التعليمات التنفيذية بلغة الآلة والمعطيات اللازمة لتخزينها ضمن الذاكرة، وما يتم لاحقًا هو أن الرابط Linker يقوم بجمع هذه الملفات مع بعضها البعض لتشكيل الملف التنفيذيّ القابل للتنفيذ من قبل المعالج.
بالإضافة للمراحل السابقة التي يتم تنفيذها أثناء عملية الترجمة، فإن الترجمة نفسها تتضمن قسمين آخرين يعملان بالتوازي مع كافة المراحل الأخرى، وهما:
جدول الرموز Symbols Table: جدول الرموز عبارة عن بنية معطيات Data-Structure يتم المحافظة عليها ضمن كافة مراحل الترجمة، حيث يقوم هذا الجدول بتخزين كافة المحددات Identifiers وأنماطها والموجودة ضمن النص البرمجيّ. استخدام جدول الرموز يسهل على المترجم البحث عن المحددات الخاصة بالمتحولات واسترجاعها أثناء مراحل عمله المختلفة.
معالجة الأخطاء Error Handling: تتضمن آلية عمل المترجم بكافة مراحله منهجية لمعالجة الأخطاء، حيث يتولى برنامجٌ آخر يعرف باسم “معالج الأخطاء Error Handler” هذه المسؤولية طوال مراحل الترجمة، وفي حال حصول خطأ نصي، قواعدي أو دلالي أثناء عملية الترجمة، يتولى معالج الأخطاء مسؤولية الكشف عنه وتوجيه رسالة خطأ تحدد ماهيته ومكان وقوعه ضمن النص البرمجيّ.
بهذه الصورة، يمكن تلخيص عملية الترجمة ومراحل عمل المترجم عبر الصورة المبسطة التالية:
أنماط أخرى من المترجمات
مع تعدد أنواع وأنماط لغات البرمجة المستخدمة، يوجد أنواع مختلفة من المترجمات، حيث يستخدم مصطلح “المترجمات الطبيعية Native Compiler” للإشارة إلى نوع المترجمات التي تمتلك معماريةً مشابهة للحاسوب أو نظام التشغيل، بحيث لا يمكن استخدام مثل هذا مترجمات على حواسيب وأنظمة تشغيل بمعمارياتٍ مختلفة. بشكلٍ مشابه، يستخدم مصطلح “المترجمات العابرة Cross Compiler” للإشارة إلى نوع المترجمات القادر على العمل على معالجات وأنظمة تشغيل مختلفة.
أيضًا، قد تكون الشيفرة الهدف التي تمثل نتيجة عمل المترجم نفسه إحدى اللغات عالية المستوى، فالمترجم Cfront الذي تم استخدامه في البداية للغة ++C عمل على تحويل الشيفرة المصدرية إلى شيفرةٍ أخرى مكتوبة بلغة C. وبهذا السياق نفسه يبرز مصطلح “المترجمات مصدر لمصدر Source-to-Source Compiler” التي تقوم بتحويل الشيفرة المصدرية المكتوبة بإحدى لغات البرمجة عالية المستوى إلى شيفرةٍ مصدريةٍ أخرى بلغة برمجة عالية المستوى مختلفة.
في عالم لغات توصيف العتاد Hardware Description Languages، يبرز مصطلح “المترجم العتادي Hardware Compiler” للإشارة إلى البرنامج الذي يقوم بتحويل الشيفرة المصدرية لملفٍ توصيفيّ يستخدم من أجل إنشاء داراتٍ إلكترونية، ولذلك فإن هذا النوع من المترجمات يعرف أيضًا باسم “أدوات الاصطناع Synthesis Tools“.
- اقرأوا أيضًا: مدخل إلى لغات توصيف العتاد HDLs
خلاصة
تمثل عملية الترجمة إحدى الركائز الأساسية في عالم البرمجة، والمترجم هو البرنامج الذي يتولى هذه المسؤولية، إذ أنه يقوم بوظيفة تحويل النص البرمجيّ من شكله عالي المستوى إلى شيفرةٍ مصدرية بلغة الآلة مفهومة من قبل الحاسوب. يمتلك المترجم وظائف أخرى هامة وهي تحليل النص البرمجيّ والتأكد من صحته بالإضافة لتحسينه بهدف جعله أكثر كفاءة من ناحية سرعة التنفيذ واستهلاكه لمساحة أقل على الذاكرة. هنالك الكثير من الأمور والمفاهيم المرتبطة بالمترجمات وكيفية عملها التي لم يتم تغطيتها ضمن هذا المقال، وذلك لأن الهدف الأساسيّ هنا هو تقديم فكرة عامة وشاملة حول المترجمات ودورها في تسهيل البرمجة في أيامنا هذه.
مصادر أخرى للاطلاع
للمزيد من التفاصيل حول المترجمات وبنائها وكيفية عملها، يمكن الاستفادة من المقالات والسلاسل التعليمية التالية:
[1] – سلسلة تعليمية من موقع TutorialPoint حول بناء وتصميم المترجمات
[2] – مقال تعليمي من موسوعة ويكيبديا الإنجليزية
[3] – سلسلة تعليمية من موقع Guru99 حول تصميم المترجمات






5 تعليقات