

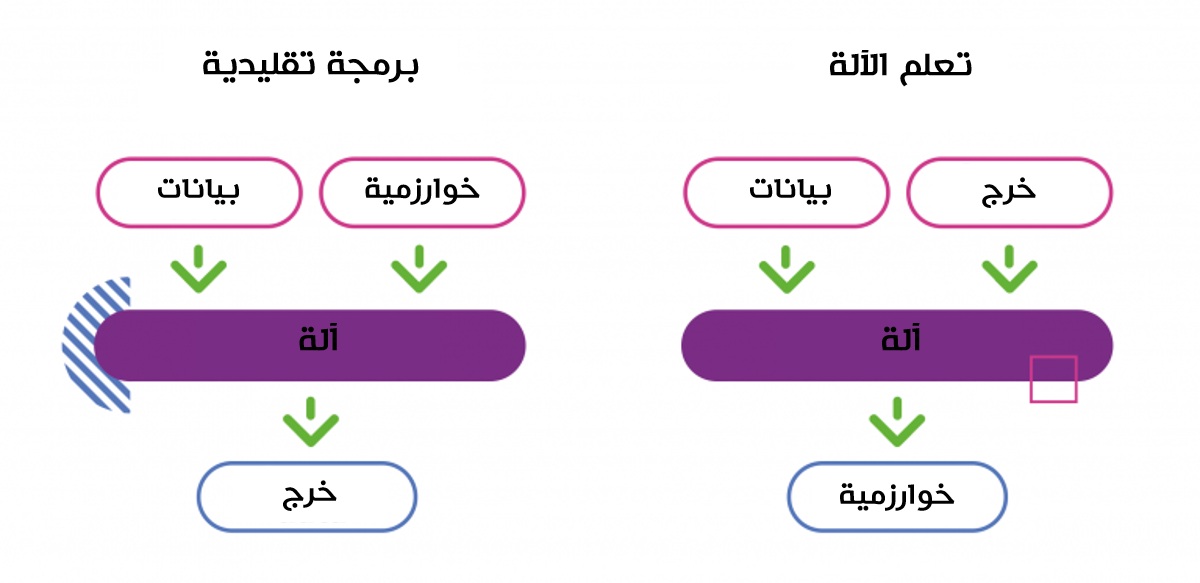
تمتلك الخوارزميات المبنية على طرق الذكاء الاصطناعي منطقاً مختلفاً عن ذلك المتبع في خوارزميات البرمجة التقليدية من ناحية العلاقة بين دخل وخرج الخوارزمية وكيفية عملها
قد تبدو هذه المعلومة غريبة بالنسبة للبعض، إلا أن الأسس النظرية للذكاء الاصطناعي موجودة منذ أكثر من 60 عاماً، إلا أنه قد تأخر نسبياً حتى أصبح مستخدماً على نطاقٍ واسع كما هو الحال اليوم. على صعيدٍ آخر، تطورت البرمجيات التقليدية بشكل كبير منذ بناء أول حاسوب حتى يومنا هذا. فلمَ احتاج الذكاء الاصطناعي حتى يومنا هذا ليتنشر بشكل كبير ويرافقنا في حياتنا اليومية؟ في هذا المقال سنستوضح إجابة هذا التساؤل ونقارن بين الذكاء الاصطناعي والبرمجة التقليدية.
- اقرأوا أيضاً: مقدمة في الذكاء الاصطناعي، تعلم الآلة والشبكات العصبونية
1. كيف نكتب برنامجاً تقليدياً
إذا أردنا برمجة خوارزمية لحل مشكلة ما فإن الطريقة التي سنتبعها هي حسب الصورة التالية:
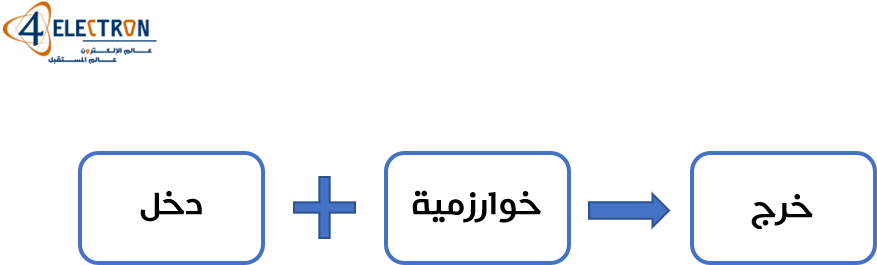
هنا المهمة الأساسية للمبرمج هي كتابة الخوارزمية بحيث نحصل على الخرج المطلوب، وعمل الخوارزمية هنا هو معالجة بيانات الدخل بشكلٍ مستمر من أجل الحصول على الخرج المطلوب. كمثال الدخل سيكون خريطة والخرج المرجو هو أقصر طريق بين نقطتين على هذه الخريطة.
لو أخذنا مثال التنبؤ بسعر عقار، فإن خوارزمية تقليدية ستحتاج إلى عددٍ من البيانات كي يتم معالجتها وتقدير سعر العقار بناءً عليها، مثل مساحة العقار، عدد غرفه وموقعه. عند إدخال هذه البيانات إلى خوارزمية المعالجة من الممكن مقارنتها مع جدول مرجعي أو بنك معلومات يتضمن معلومات حول أسعار العقارات بحسب مساحتها، عدد غرفها وموقعها، وما ستقوم به خوارزميتنا بهذه الحالة هو إجراء مقارنة بين معلومات والدخل وبنك المعلومات واختيار السعر (أو حسابه) بناءً على ذلك.
من المهم هنا الانتباه إلى نقطة هامة: البرنامج السابق ثابت وقدرته على تحديد سعر العقار محدودة بطريقة معالجة الخوارزمية للبيانات. في حال أردنا تحسين دقة الخوارزمية، فعلينا إعادة كتابة البرنامج وترجمته للغة الآلة وتوليد الملف التنفيذي وتجريبه من جديد (هذا ما يحصل مثلاً عند تحديث التطبيقات والبرامج على الهواتف الذكية والحواسيب الشخصية).
- اقرأوا أيضاً: مدخل إلى لغات ونماذج البرمجة
- اقرأوا أيضاً: ما هو نموذج البرمجة الإجرائية (الحتمية)
2. كيف نبني نموذج ذكاء اصطناعي
نظراً للانتشار الواسع لتطبيقات الذكاء الاصطناعي المبنية على طرق تعلم الآلة Machine Learning، سنحصر مثالنا في هذا المقال على تطبيقٍ يعتمد على نموذج تعلم آلة من أجل حل مشكلة معينة.
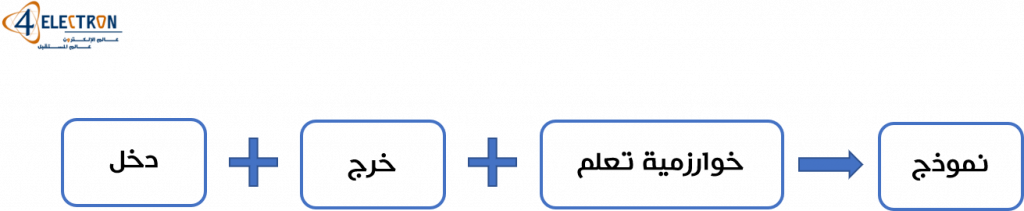
هنا يحتاج المطور إلى دخل وخرج وخوارزمية تعلُّم وبناءً على هذه المعطيات سنحصل على نموذج يمكن استخدامه فيما بعد. الفارق مع التطبيقات المبنية على خوارزميات البرمجة التقليدية هو أن التطبيقات المبنية على نماذج تعلم الآلة تحتاج في البداية إلى عملية تدريب قبل أن تكون قادرة على تنفيذ المهمة المطلوبة منها.
خلال عملية التدريب (أو التعلم)، يتم إدخال البيانات المطلوب التي سيتم معالجتها، بالإضافة للخرج المتوقع، والهدف هو تعليم النموذج كيف يقوم بمعالجة البيانات من أجل الوصول إلى الخرج المطلوب. بمعنى آخر، نحن نقوم بإخبار نموذج تعلم الآلة أثناء عملية التدريب حول الهدف الذي نطمح للوصول إليه، وبتكرار عملية التدريب يقوم النموذج بتحسين أدائه عبر المقارنة المستمرة بين بيانات الدخل والخرج المطلوب. يجب الإشارة هنا إلى أن المثال السابق هو لنماذج تعلم الآلة الخاضعة للإشراف أو الموجهة Supervised Learning وهنالك نمط آخر من النماذج التي لا تكون خاضعة للإشراف Unsupervised Learning ، بمعنى أن عملية التدريب نفسها تتضمن تعليم النموذج كيفية التعرف على الخرج الواجب الوصول إليه، ومن ثم تحسين دقة الخرج عبر إجراء عمليات تدريب متتالية.
على سبيل المثال باستخدام تعلم الآلة يمكننا بناء نموذج يمكنه التنبؤ بسعر عقار ما. في البداية سنحتاج إلى بيانات حول العقارات التي تم بيعها، وهكذا يكون الدخل بيانات حول مساحة العقار، عدد الغرف، الموقع. بنفس الوقت سنحتاج إلى وسم متناسب مع بيانات الدخل (وهو الخرج المتوقع)، مثل القول أنه بالنسبة لعقار بمساحة 100 متر مربع وبعدد غرق قدره ثلاثة وبموقعٍ مركزيّ ضمن المدينة فإن السعر سيكون مرتفع، بينما عقار وبنفس المساحة وعدد الغرف ولكن بموقعٍ بعيد عن مركز المدينة سيكون ذو سعر منخفض. عندما ندخل البيانات للنموذج مع إضافة وسم لكل حزمة بيانات، فإننا نساعد النموذج على معرفة كيفية اتخاذ قرار بشأن تحديد سعر العقار. أخيراً، وبعد الانتهاء من التدريب سيصبح النموذج قادراً لوحده على تقدير أسعار العقارات اعتماداً فقط على بيانات الدخل بدون الحاجة لبيانات خرج أو وسوم إضافية.
بالمقارنة مع البرامج المبنية على الخوارزميات التقليدية، سنجد أن البرنامج المبني على نموذج تعلم الآلة يمتلك قدرة ذاتية على تحسين دقته بدون الحاجة لتحديثه وتعديل الشيفرة المصدرية الخاصة به. على صعيدٍ آخر، برامج وتطبيقات تعلم الآلة “تتعلم” كيفية التنبؤ بالخرج وكيفية تحسين دقتها، بينما البرامج والتطبيقات التقليدية محدودة بالخوارزميات المكتوبة أصلاً من قبل المبرمجين.
بهذه الطريقة، يمكن تلخيص الفرق بين طرق البرمجة التقليدية وطرق البرمجة المبنية على نماذج الذكاء الاصطناعي على أننا بحالة البرمجة التقليدية نهدف لمعرفة “الخرج” بينما في البرمجة في مجال الذكاء الاصطناعي فإننا نهدف لبناء الخوارزمية نفسها عبر عملية التدريب والتعليم التي يتلقاها نموذج الذكاء الاصطناعي.

3. هل ستندثر البرمجة التقليدية؟
لا. من الجدير بالذكر أن البرمجيات المبنية على نماذج الذكاء الاصطناعي لا تمثل بديلاً عن البرمجة التقليدية إنما مُكمل لها. على سبيل المثال إذا أردنا برمجة تطبيق للتنبؤ بسعر عقار فيمكن استخدام النموذج الذي تم تعليمه في الفقرة السابقة للحصول على النتائج أما واجهة المستخدم ستكون مبرمجة بطريقة تقليدية. وهذا ليس للحصر، إن البرمجة والخوارزميات التقليدية ستكون موجودة في المستقبل وليس فقط من خلال واجهات المُستخدم.
4. أين تُستخدم البرمجة التقليدية
يُفضل استخدام البرمجة التقليدية في الحلات التالية:
1. سرعة النتائج غير مهمة جداً
2. دقة النتائج مهمة جداً
3. القدرة على تتبع العمليات المجراة وتفسير النتائج مهمة جداً
4. في المجالات الخاضعة لتنظيم شديد
5. أين يُستخدم الذكاء الاصطناعي
يُفضل استخدام الذكاء الاصطناعي في الحالات التالية:
1. سرعة النتائج مهمة
2. دقة النتائج أقل أهمية
3. قلة أهمية تفسير النتائج
4. في المجالات الخاضعة لتنظيم أقل
6. محاسن ومساوئ البرمجة التقليدية
كما ذكرنا سابقأ يُستحسن استخدام البرمجة التقليدية عندما يكو هنالك حاجة لتتبعٍ أفضل للنتائج، إذ أنها تعطي شفافية أكبر ويمكن تفسير كل خطوة وكل نتيجة سينتجها البرنامج. هذه هي الطريقة المفضلة في المجالات عالية التنظيم وحيث تلعب جوانب مثل درجة الحماية أولويات قصوى. بمثل هكذا مجالات، لا يمكن التعامل إلا مع معلومات محددة وحتمية، لأن خطأ احتمالي بسيط قد يؤدي لفشل النظام بالكامل، وما تقوم به نماذج الذكاء الاصطناعي هو حساب أرجحية Likelihood، التي هي نسبة مئوية متغيرة وليست قيمة ثابتة محددة وحتمية. على الرغم من ذلك فقد بدأ الذكاء الاصطناعي بالفعل دخول هذه المجالات ولكن على نطاق محدود. نظراً لشفافية البرمجة التقليدية وحتميتها فإنها تلقي عبئاً كبيراً على المبرمج إذا يجب عليه تضمين جميع الاحتمالات التي من الممكن أن يواجهها البرنامج خلال الاستخدام. وإن إهمال احتمال واحد فقط قد يؤدي إلى نتائج كارثية.
7. محاسن ومساوئ الذكاء الاصطناعي
عند كتابة برنامج تقليدي فإنه لا مفر من تعريف جميع المدخلات مهما كان تعدادها أو نوعها. وهذا الأمر يمكن التعامل معه عندما يكون عدد المُدخلات محدوداً 1، 100 أو حتى 1000 على سبيل المثال ولكن ماذا إذا كنا بحاجة مليون أو مليار مُدخل؟ في هذه الحالة فإنه من الصعب التعامل مع هذا الكم الكبير من المدخلات يدوياً وهنا يُمكن استخدام نموذج تعلم آلة يمكنه التعامل مع كم المُدخلات الكبير. أضف إلى ذلك مرونة الذكاء الاصطناعي وقدرته على التكيف مع التغيرات دون الحاجة إلى تعريف مسبق لهذه التغيرات كما هو الحال مع البرنامج التقليدي. من ناحية أخرى فإن كم البيانات الهائل المستخدم لتعليم نموذج ذكي يجعل عملية تتبع وتفسير النتائج صعبة جداً أو شبه مستحيلة.
من المخاوف السائدة اليوم هي أن الذكاء الاصطناعي يستهلك كميات كبير من الطاقة خلال عملية التعلم والتدريب، إذ أن عملية التعلم هذه تحتاج إلى عدد كبير من العمليات الحسابية التي تُجرى عادة على وحدات المعالجة الرسومية GPUs. من الصعب إجراء مُقارنة مباشرة بين الذكاء الاصطناعي والخوارزميات التقليدية من ناحية استهلاك الطاقية. لكن هناك أبحاث كثرة تتعمق في كيفية جعل عملية التعلم أكثر كفاءة. أضف إلى ذلك هناك أدوات تُقدِّر انبعاثات غاز ثاني أوكسيد الكربون الناتجة عن عملية التعلم.
8. لماذا الآن؟
كما ذكرنا من قبل إن أُسس الذكاء الاصطناعي موجودة منذ أكثر من 60 عاماً فلِمَ احتجنا حتى يومنا هذا كي نرى تطبيقاته العملية في حياتنا اليومية بينما الخوارزميات التقليدية كانت ومازالت مستخدمة وبكثرة؟
يمكن الإجابة على هذا التساؤل بالعودة إلى كيفية تطوير نموذج ذكاء اصطناعي. فلكي يتم تعليم النموذج فنحن بحاجة إلى كمية كبير البيانات لتكون أساس عملية التعلم. وإن زيادة حجم البيانات يتناسب طردأ مع جودة النموذج الناتج ودقته. لذا كان من الصعب تعليم نماذج ذكية في الحقبة الماضية نظراً لشُح البيانات المجموعة في ذلك الوقت. بينما الخوارزميات التقليدية ليست بحاجة إلى الكمية الهائلة من البيانات التي يحتاجها الذكاء الاصطناعي.
خلاصة
- تنتشر البرمجيات المعتمدة على نماذج وخوارزميات الذكاء الاصطناعي بشكلٍ كبير في الوقت الحالي
- هنالك اختلاف في طريقة التفكير وآلية معالجة الأمور بين البرمجيات المعتمدة على خوارزميات الذكاء الاصطناعي وتلك المعتمدة على الخوارزميات البرمجية الإجرائية أو الحتمية
- الخوارزميات والطرق البرمجية التقليدية جيدة في المجالات التي يكون هنالك فيها حاجة لخرج محدد وحتمي، ولكنها سيئة من ناحية صعوبة بناء برامج قادرة على التعامل مع عدد كبيرة من المتحولات كما أن تحسين دقة البرنامج يتطلب إعادة كتابته وترجمته وتوليد الملف التنفيذي من جديد
- البرامج المعتمدة على طرق ونماذج الذكاء الاصطناعي مرنة أكثر وتمتلك قدرة كبيرة على التعامل مع كمية مدخلات كبيرة، وهي تمتلك قدرة على تطوير نفسها بسبب خاصية التعلم التي تمتلكها نماذج تعلم الآلة
- في السابق كان القول السائد أنه من يمتلك أفضل خوارزمية سيُسطر على مجال ما، لكن هذه المقولة لم تعد دقيقة تماماً في يومنا هذا، إنما الأدق هو أنه من يمتلك أكبر كمية من البيانات سيُسطر.








تعليق واحد